class: center middle main-title section-title-7 # DAGs and<br>potential outcomes .class-info[ **Session 5** .light[PMAP 8521: Program evaluation<br> Andrew Young School of Policy Studies ] ] --- name: outline class: title title-inv-8 # Plan for today -- .box-5.medium.sp-after-half[*do*()ing observational<br>causal inference] -- .box-7.medium[Potential outcomes] --- name: dag-adjustment class: center middle section-title section-title-5 animated fadeIn # *do*()ing observational<br>causal inference --- layout: true class: title title-5 --- # Structural models .box-inv-5.small[The relationship between nodes can be described with equations] .pull-left[ $$ `\begin{aligned} \text{Loc} &= f_\text{Loc}(\text{U1}) \\ \text{Bkgd} &= f_\text{Bkgd}(\text{U1}) \\ \text{JobCx} &= f_\text{JobCx}(\text{Edu}) \\ \text{Edu} &= f_\text{Edu}(\text{Req}, \text{Loc}, \text{Year}) \\ \text{Earn} &= f_\text{Earn}(\text{Edu}, \text{Year}, \text{Bkgd}, \\ & \quad\quad\quad\quad \text{Loc}, \text{JobCx}) \\ \end{aligned}` $$ ] .pull-right[ <img src="05-slides_files/figure-html/structural-dag-1.png" width="90%" style="display: block; margin: auto;" /> ] --- # Structural models .box-inv-5[`dagify()` in **ggdag** forces you to think this way] .pull-left.small[ $$ `\begin{aligned} \text{Earn} &= f_\text{Earn}(\text{Edu}, \text{Year}, \text{Bkgd}, \\ & \quad\quad\quad\quad \text{Loc}, \text{JobCx}) \\ \text{Edu} &= f_\text{Edu}(\text{Req}, \text{Loc}, \text{Year}) \\ \text{JobCx} &= f_\text{JobCx}(\text{Edu}) \\ \text{Bkgd} &= f_\text{Bkgd}(\text{U1}) \\ \text{Loc} &= f_\text{Loc}(\text{U1}) \end{aligned}` $$ ] .pull-right.small-code[ ```r dagify( Earn ~ Edu + Year + Bkgd + Loc + JobCx, Edu ~ Req + Loc + Bkgd + Year, JobCx ~ Edu, Bkgd ~ U1, Loc ~ U1 ) ``` ] --- # Causal identification .pull-left-narrow[ .box-inv-5[All these nodes are related; there's correlation between them all] .box-inv-5[We care about<br>**Edu → Earn**, but what do we do about all the other nodes?] ] .pull-right-wide[ <img src="05-slides_files/figure-html/edu-earn-full-1.png" width="100%" style="display: block; margin: auto;" /> ] --- # Causal identification .box-inv-5.medium[A causal effect is *identified* if the association between treatment and outcome is propertly stripped and isolated] --- # Paths and associations .box-inv-5.medium[Arrows in a DAG transmit associations] .box-inv-5.medium[You can redirect and control those paths by "adjusting" or "conditioning"] --- # Three types of associations .pull-left-3[ .box-5.medium[Confounding] <img src="05-slides_files/figure-html/confounding-dag-1.png" width="100%" style="display: block; margin: auto;" /> .box-inv-5.small[Common cause] ] .pull-middle-3.center[ .box-5.medium[Causation] <img src="05-slides_files/figure-html/mediation-dag-1.png" width="100%" style="display: block; margin: auto;" /> .box-inv-5.small[Mediation] ] .pull-right-3[ .box-5.medium[Collision] <img src="05-slides_files/figure-html/collision-dag-1.png" width="100%" style="display: block; margin: auto;" /> .box-inv-5.small[Selection /<br>endogeneity] ] --- # Interventions .box-inv-5.medium[*do*-operator] .box-5[Making an intervention in a DAG] $$ P[Y\ |\ do(X = x)] \quad \text{or} \quad E[Y\ |\ do(X = x)] $$ -- .box-5[P = probability distribution, or E = expectation/expected value] -- .box-5[Y = outcome, X = treatment;<br>x = specific value of treatment] --- # Interventions $$ E[Y\ |\ do(X = x)] $$ .box-5[E\[ Earnings | *do*(One year of college)\] ] -- .box-5[E\[ Firm growth | *do*(Government R&D funding)\] ] -- .box-5[E\[ Air quality | *do*(Carbon tax)\] ] -- .box-5[E\[ Juvenile delinquency | *do*(Truancy program)\] ] -- .box-5[E\[ Malaria infection rate | *do*(Mosquito net)\] ] --- # Interventions .box-inv-5[When you *do*() X, delete all arrows into it] -- .pull-left[ .box-5.small[Observational DAG] <img src="05-slides_files/figure-html/observational-dag-1.png" width="90%" style="display: block; margin: auto;" /> ] -- .pull-right[ .box-5.small[Experimental DAG] <img src="05-slides_files/figure-html/experimental-dag-1.png" width="90%" style="display: block; margin: auto;" /> ] --- # Interventions $$ E[\text{Earnings}\ |\ do(\text{College education})] $$ -- .pull-left[ .box-5.small[Observational DAG] <img src="05-slides_files/figure-html/edu-earn-obs-1.png" width="90%" style="display: block; margin: auto;" /> ] -- .pull-right[ .box-5.small[Experimental DAG] <img src="05-slides_files/figure-html/edu-earn-experiment-1.png" width="90%" style="display: block; margin: auto;" /> ] --- # Un*do*()ing things .box-inv-5.medium[We want to know **P[Y | *do*(X)]**<br>but all we have is<br>observational data X, Y, and Z] -- $$ P[Y\ |\ do(X)] \neq P(Y\ |\ X) $$ -- .box-5[Correlation isn't causation!] --- # Un*do*()ing things .box-inv-5.medium[Our goal with observational data:<br>Rewrite **P[Y | *do*(X)]** so that it doesn't have a *do*() anymore (is "*do*-free")] --- # *do*-calculus .box-inv-5[A set of three rules that let you manipulate a DAG<br>in special ways to remove *do*() expressions] .center[ <figure> <img src="img/05/do-calculus.png" alt="do-calculus rules" title="do-calculus rules" width="40%"> </figure> ] .box-5.smaller[WAAAAAY beyond the score of this class!<br>Just know it exists and computer algorithms can do it for you!] ??? https://arxiv.org/abs/1906.07125 --- # Special cases of *do*-calculus .box-inv-5.medium.sp-after[Backdoor adjustment] .box-inv-5.medium[Frontdoor adjustment] --- # Backdoor adjustment $$ P[Y\ |\ do(X)] = \sum_Z P(Y\ |\ X, Z) \times P(Z) $$ .pull-left[ <img src="05-slides_files/figure-html/backdoor-dag-1.png" width="90%" style="display: block; margin: auto;" /> ] .pull-right[ .box-inv-5.small[↑ That's complicated!] .box-inv-5[The right-hand side of the equation means "the effect of X on Y after adjusting for Z"] .box-5[There's no *do*() on that side!] ] --- # Frontdoor adjustment <img src="05-slides_files/figure-html/frontdoor-1.png" width="50%" style="display: block; margin: auto;" /> .box-5.small[**S → T** is *d*-separated; **T → C** is *d*-separated<br>combine the effects to find **S → C**] --- # Moral of the story .box-inv-5.medium[If you can transform *do*() expressions to<br>*do*-free versions, you can legally make causal inferences from observational data] -- .box-5[Backdoor adjustment is easiest to see +<br>dagitty and **ggdag** do this for you!] -- .box-5.small[Fancy algorithms (found in the **causaleffect** package)<br>can do the official *do*-calculus for you too] --- layout: false name: potential-outcomes class: center middle section-title section-title-7 animated fadeIn # Potential outcomes --- layout: true class: title title-7 --- # Program effect <figure> <img src="img/05/program-effect-letters.png" alt="Outcomes and program effect" title="Outcomes and program effect" width="100%"> </figure> --- # Some equation translations .box-inv-7.medium[Causal effect = δ (delta)] $$ \delta = P[Y\ |\ do(X)] $$ -- $$ \delta = E[Y\ |\ do(X)] - E[Y\ |\ \hat{do}(X)] $$ -- $$ \delta = (Y\ |\ X = 1) - (Y\ |\ X = 0) $$ -- $$ \delta = Y_1 - Y_0 $$ --- layout: false class: bg-full background-image: url("img/05/TAL.png") ??? https://www.thisamericanlife.org/691/gardens-of-branching-paths --- layout: true class: title title-7 --- layout: false .box-7.large[Fundamental problem<br>of causal inference] $$ \delta_i = Y_i^1 - Y_i^0 \quad \text{in real life is} \quad \delta_i = Y_i^1 - ??? $$ .box-inv-7[Individual-level effects are impossible to observe!] .box-inv-7[There are no individual counterfactuals!] --- layout: true class: title title-7 --- # Average treatment effect (ATE) .box-inv-7.medium[Solution: Use averages instead] $$ \text{ATE} = E(Y_1 - Y_0) = E(Y_1) - E(Y_0) $$ -- .box-7[Difference between average/expected value when<br>program is on vs. expected value when program is off] $$ \delta = (\bar{Y}\ |\ P = 1) - (\bar{Y}\ |\ P = 0) $$ --- layout: false .small[ | Person | Age | Treated | Outcome<br>with program | Outcome<br>without program | Effect | |:------:|:-----:|:-------:|:-----------------------:|:--------------------------:|:-------:| | 1 | Old | TRUE | **80** | 60 | **20** | | 2 | Old | TRUE | **75** | 70 | **5** | | 3 | Old | TRUE | **85** | 80 | **5** | | 4 | Old | FALSE | 70 | **60** | **10** | | 5 | Young | TRUE | **75** | 70 | **5** | | 6 | Young | FALSE | 80 | **80** | **0** | | 7 | Young | FALSE | 90 | **100** | **-10** | | 8 | Young | FALSE | 85 | **80** | **5** | ] --- .smaller.sp-after[ | Person | Age | Treated | Outcome<br>with program | Outcome<br>without program | Effect | |:------:|:-----:|:-------:|:-----------------------:|:--------------------------:|:-------:| | 1 | Old | TRUE | **80** | 60 | **20** | | 2 | Old | TRUE | **75** | 70 | **5** | | 3 | Old | TRUE | **85** | 80 | **5** | | 4 | Old | FALSE | 70 | **60** | **10** | | 5 | Young | TRUE | **75** | 70 | **5** | | 6 | Young | FALSE | 80 | **80** | **0** | | 7 | Young | FALSE | 90 | **100** | **-10** | | 8 | Young | FALSE | 85 | **80** | **5** | ] .pull-left.small[ `\(\delta = (\bar{Y}\ |\ P = 1) - (\bar{Y}\ |\ P = 0)\)` ] .pull-right.small[ `\(\text{ATE} = \frac{20 + 5 + 5 + 5 + 10 + 0 + -10 + 5}{8} = 5\)` ] --- class: title title-7 # CATE .box-inv-7.sp-after[ATE in subgroups] -- .box-7.medium[Is the program more<br>effective for specific age groups?] --- .smaller.sp-after[ | Person | Age | Treated | Outcome<br>with program | Outcome<br>without program | Effect | |:------:|:-----:|:-------:|:-----------------------:|:--------------------------:|:-------:| | 1 | Old | TRUE | **80** | 60 | **20** | | 2 | Old | TRUE | **75** | 70 | **5** | | 3 | Old | TRUE | **85** | 80 | **5** | | 4 | Old | FALSE | 70 | **60** | **10** | | 5 | Young | TRUE | **75** | 70 | **5** | | 6 | Young | FALSE | 80 | **80** | **0** | | 7 | Young | FALSE | 90 | **100** | **-10** | | 8 | Young | FALSE | 85 | **80** | **5** | ] .pull-left.small[ `\(\delta = (\bar{Y}_\text{O}\ |\ P = 1) - (\bar{Y}_\text{O}\ |\ P = 0)\)` `\(\delta = (\bar{Y}_\text{Y}\ |\ P = 1) - (\bar{Y}_\text{Y}\ |\ P = 0)\)` ] .pull-right.small[ `\(\text{CATE}_\text{Old} = \frac{20 + 5 + 5 + 10}{4} = 10\)` `\(\text{CATE}_\text{Young} = \frac{5 + 0 - 10 + 5}{4} = 0\)` ] --- class: title title-7 # ATT and ATU .box-inv-7.medium[Average treatment on the treated] .box-7[ATT / TOT] .box-7[Effect for those with treatment] -- .box-inv-7.medium[Average treatment on the untreated] .box-7[ATU / TUT] .box-7[Effect for those without treatment] --- .smaller.sp-after[ | Person | Age | Treated | Outcome<br>with program | Outcome<br>without program | Effect | |:------:|:-----:|:-------:|:-----------------------:|:--------------------------:|:-------:| | 1 | Old | TRUE | **80** | 60 | **20** | | 2 | Old | TRUE | **75** | 70 | **5** | | 3 | Old | TRUE | **85** | 80 | **5** | | 4 | Old | FALSE | 70 | **60** | **10** | | 5 | Young | TRUE | **75** | 70 | **5** | | 6 | Young | FALSE | 80 | **80** | **0** | | 7 | Young | FALSE | 90 | **100** | **-10** | | 8 | Young | FALSE | 85 | **80** | **5** | ] .pull-left.small[ `\(\delta = (\bar{Y}_\text{T}\ |\ P = 1) - (\bar{Y}_\text{T}\ |\ P = 0)\)` `\(\delta = (\bar{Y}_\text{U}\ |\ P = 1) - (\bar{Y}_\text{U}\ |\ P = 0)\)` ] .pull-right.small[ `\(\text{CATE}_\text{Treated} = \frac{20 + 5 + 5 + 5}{4} = 8.75\)` `\(\text{CATE}_\text{Untreated} = \frac{10 + 0 - 10 + 5}{4} = 1.25\)` ] --- layout: true class: title title-7 --- # ATE, ATT, and ATU .box-inv-7.medium.sp-after[The ATE is the weighted average<br>of the ATT and ATU] -- .center[ `\(\text{ATE} = (\pi_\text{Treated} \times \text{ATT}) + (\pi_\text{Untreated} \times \text{ATU})\)` `\((\frac{4}{8} \times 8.75) + (\frac{4}{8} \times 1.25)\)` `\(4.375 + 0.625 = 5\)` ] .box-7.smaller[**π** here means "proportion," not 3.1415] --- # Selection bias .box-inv-7.medium[ATE and ATT aren't always the same] .box-inv-7.medium[ATE = ATT + Selection bias] $$ `\begin{aligned} 5 &= 8.75 + x \\ x &= -3.75 \end{aligned}` $$ .box-7[Randomization fixes this, makes x = 0] --- # Actual data .pull-left.smaller[ | Person | Age | Treated | Actual outcome | |:------:|:-----:|:-------:|:--------------:| | 1 | Old | TRUE | 80 | | 2 | Old | TRUE | 75 | | 3 | Old | TRUE | 85 | | 4 | Old | FALSE | 60 | | 5 | Young | TRUE | 75 | | 6 | Young | FALSE | 80 | | 7 | Young | FALSE | 100 | | 8 | Young | FALSE | 80 | ] .pull-right[ .box-inv-7[Treatment not<br>randomly assigned] .box-inv-7[We can't see<br>unit-level causal effects] .box-7[What do we do?!] ] --- # Actual data .pull-left.smaller[ | Person | Age | Treated | Actual outcome | |:------:|:-----:|:-------:|:--------------:| | 1 | Old | TRUE | 80 | | 2 | Old | TRUE | 75 | | 3 | Old | TRUE | 85 | | 4 | Old | FALSE | 60 | | 5 | Young | TRUE | 75 | | 6 | Young | FALSE | 80 | | 7 | Young | FALSE | 100 | | 8 | Young | FALSE | 80 | ] .pull-right[ .box-inv-7[Treatment seems to be correlated with age] <img src="05-slides_files/figure-html/po-dag-1.png" width="100%" style="display: block; margin: auto;" /> ] --- # Actual data .pull-left.tiny[ | Person | Age | Treated | Actual outcome | |:------:|:-----:|:-------:|:--------------:| | 1 | Old | TRUE | 80 | | 2 | Old | TRUE | 75 | | 3 | Old | TRUE | 85 | | 4 | Old | FALSE | 60 | | 5 | Young | TRUE | 75 | | 6 | Young | FALSE | 80 | | 7 | Young | FALSE | 100 | | 8 | Young | FALSE | 80 | ] .pull-right[ .box-inv-7[We can estimate the ATE by finding the weighted average of age-based CATEs] .box-inv-7.tiny[As long as we assume/pretend treatment was randomly assigned within each age = unconfoundedness] ] .center[ `\(\widehat{\text{ATE}} = \pi_\text{Old} \widehat{\text{CATE}_\text{Old}} + \pi_\text{Young} \widehat{\text{CATE}_\text{Young}}\)` ] --- # Actual data .center.sp-after[ `\(\color{#FF851B}{\widehat{\text{ATE}}} = \pi_\text{Old} \color{#2ECC40}{\widehat{\text{CATE}_\text{Old}}} + \pi_\text{Young} \color{#0074D9}{\widehat{\text{CATE}_\text{Young}}}\)` ] .pull-left-narrow.tiny[ | Person | Age | Treated | Actual outcome | |:------:|:-----:|:-------:|:--------------:| | 1 | Old | TRUE | 80 | | 2 | Old | TRUE | 75 | | 3 | Old | TRUE | 85 | | 4 | Old | FALSE | 60 | | 5 | Young | TRUE | 75 | | 6 | Young | FALSE | 80 | | 7 | Young | FALSE | 100 | | 8 | Young | FALSE | 80 | ] .pull-right-wide.small[ `\(\color{#2ECC40}{\widehat{\text{CATE}_\text{Old}}} = \frac{80 + 75 + 85}{3} - \frac{60}{1} = \color{#2ECC40}{20}\)` `\(\color{#0074D9}{\widehat{\text{CATE}_\text{Young}}} = \frac{75}{1} - \frac{80 + 100 + 80}{3} = \color{#0074D9}{-11.667}\)` `\(\color{#FF851B}{\widehat{\text{ATE}}} = (\frac{4}{8} \times \color{#2ECC40}{20}) + (\frac{4}{8} \times \color{#0074D9}{-11.667}) = \color{#FF851B}{4.1667}\)` ] --- # ¡¡¡DON'T DO THIS!!! .center.sp-after[ `\(\color{#FF851B}{\widehat{\text{ATE}}} = \color{#F012BE}{\widehat{\text{CATE}_\text{Treated}}} - \color{#AAAAAA}{\widehat{\text{CATE}_\text{Untreated}}}\)` ] .pull-left-narrow.tiny[ | Person | Age | Treated | Actual outcome | |:------:|:-----:|:-------:|:--------------:| | 1 | Old | TRUE | 80 | | 2 | Old | TRUE | 75 | | 3 | Old | TRUE | 85 | | 4 | Old | FALSE | 60 | | 5 | Young | TRUE | 75 | | 6 | Young | FALSE | 80 | | 7 | Young | FALSE | 100 | | 8 | Young | FALSE | 80 | ] .pull-right-wide.small.center[ `\(\color{#F012BE}{\widehat{\text{CATE}_\text{Treated}}} = \frac{80 + 75 + 85 + 75}{4} = \color{#F012BE}{78.75}\)` `\(\color{#AAAAAA}{\widehat{\text{CATE}_\text{Untreated}}} = \frac{60 + 80 + 100 + 80}{4} = \color{#AAAAAA}{80}\)` `\(\color{#FF851B}{\widehat{\text{ATE}}} = \color{#F012BE}{78.75} - \color{#AAAAAA}{80} = \color{#FF851B}{-1.25}\)` .box-7[You can only do this if treatment is random!] ] --- # Matching and ATEs .center[ `\(\widehat{\text{ATE}} = \pi_\text{Old} \widehat{\text{CATE}_\text{Old}} + \pi_\text{Young} \widehat{\text{CATE}_\text{Young}}\)` ] .pull-left-wide[ .box-inv-7[We used age here because it correlates with (and confounds) the outcome] .box-7.small[And we assumed unconfoundedness;<br>that treatment is<br>randomly assigned within the groups] ] .pull-right-narrow[ 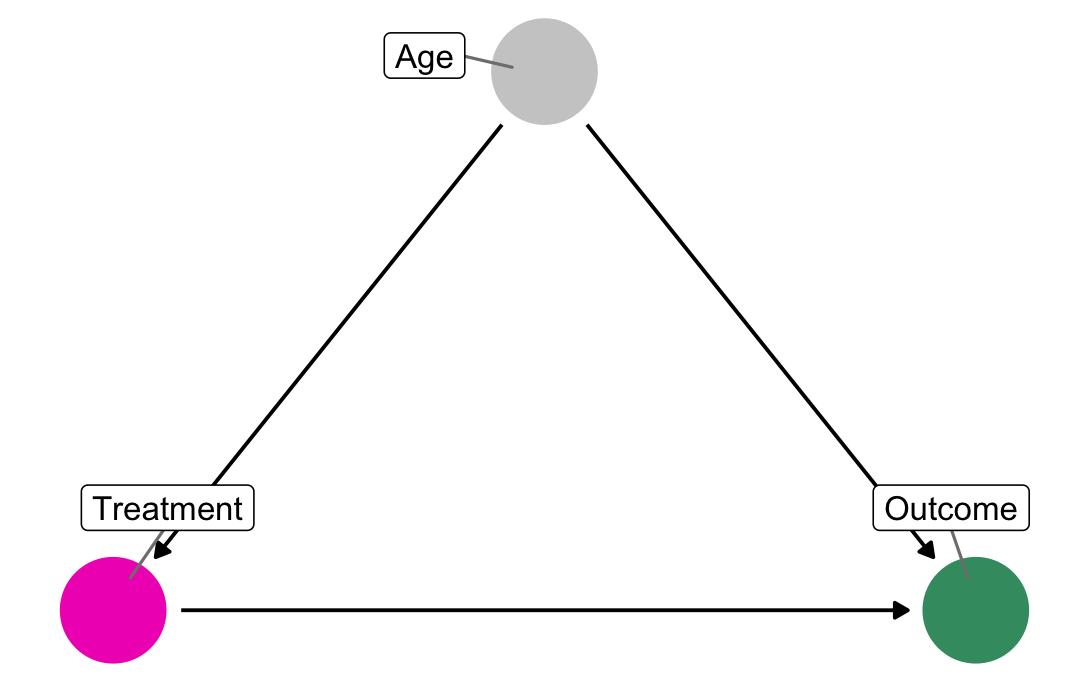 ] --- layout: false .pull-left-narrow[ .box-7[Does attending a private university cause an increase in earnings?] ] .pull-right-wide[ <figure> <img src="img/05/mm-matching.png" alt="Matching table from Mastering 'Metrics" title="Matching table from Mastering 'Metrics" width="100%"> </figure> ] --- .pull-left-wide[ <figure> <img src="img/05/mm-matching.png" alt="Matching table from Mastering 'Metrics" title="Matching table from Mastering 'Metrics" width="90%"> </figure> ] .pull-right-narrow[ .box-7[This is tempting!] .box-inv-7[Average private − Average public] .tiny[ $$ `\begin{aligned} \frac{110 + 100 + 60 + 115 + 75}{5} &= \color{#0074D9}{92} \\ \frac{110 + 30 + 90 + 60}{4} &= \color{#2ECC40}{72.5} \\ (\color{#0074D9}{92} \times \color{#7FDBFF}{\frac{5}{9}}) - (\color{#2ECC40}{72.5} \times \color{#01FF70}{\frac{4}{9}}) &= \color{#FF851B}{18,888} \end{aligned}` $$ ] .box-7[**This is wrong!**] ] .center[ `\(\color{#FF851B}{\widehat{\text{ATE}}} = \color{#7FDBFF}{\pi_\text{Private}} \color{#0074D9}{\widehat{\text{CATE}_\text{Private}}} + \color{#01FF70}{\pi_\text{Public}} \color{#2ECC40}{\widehat{\text{CATE}_\text{Public}}}\)` ] --- class: title title-7 # Grouping and matching .pull-left[ <figure> <img src="img/05/mm-matching.png" alt="Matching table from Mastering 'Metrics" title="Matching table from Mastering 'Metrics" width="100%"> </figure> ] .pull-right[ .box-inv-7[These groups look like they have similar characteristics] .box-inv-7.tiny[Unconfoundedness?] <img src="05-slides_files/figure-html/match-dag-1.png" width="80%" style="display: block; margin: auto;" /> ] --- .pull-left-wide[ <figure> <img src="img/05/mm-matching.png" alt="Matching table from Mastering 'Metrics" title="Matching table from Mastering 'Metrics" width="90%"> </figure> ] .pull-right-narrow[ .box-inv-7[CATE Group A + CATE Group B] .tiny[ $$ `\begin{aligned} \frac{110 + 100}{2} - 110 &= \color{#0074D9}{-5,000} \\ 60 - 30 &= \color{#2ECC40}{30,000} \\ (\color{#0074D9}{-5} \times \color{#7FDBFF}{\frac{3}{5}}) + (\color{#2ECC40}{30} \times \color{#01FF70}{\frac{2}{5}}) &= \color{#FF851B}{9,000} \end{aligned}` $$ ] .box-7[**This is less wrong!**] ] .center[ `\(\color{#FF851B}{\widehat{\text{ATE}}} = \color{#7FDBFF}{\pi_\text{Group A}} \color{#0074D9}{\widehat{\text{CATE}_\text{Group A}}} + \color{#01FF70}{\pi_\text{Group B}} \color{#2ECC40}{\widehat{\text{CATE}_\text{Group B}}}\)` ] --- class: title title-7 # Matching with regression $$ \text{Earnings} = \alpha + \beta_1 \text{Private} + \beta_2 \text{Group} + \epsilon $$ -- .small-code.center[ ```r model_earnings <- lm(earnings ~ private + group_A, data = schools_small) ``` ] -- .small[ |term | estimate| std.error| statistic| p.value| |:-----------|--------:|---------:|---------:|-------:| |(Intercept) | 40000| 11952.29| 3.35| 0.08| |privateTRUE | 10000| 13093.07| 0.76| 0.52| |group_ATRUE | 60000| 13093.07| 4.58| 0.04| ] -- .center.float-left[ .box-7[β<sub>1</sub> = $10,000] .box-7[This is less wrong!] .box-7[Significance details!] ]